Wenn uns die jüngere Geschichte eines gezeigt hat, dann wie schnell Technologie unser Leben verändern kann. Denken Sie nur an den Durchbruch des Internets oder die revolutionären Veränderungen durch die Einführung des ersten Smartphones. Jetzt erleben wir einen weiteren tiefgreifenden technologischen Wandel, angetrieben durch die innovativen Durchbrüche der Künstlichen Intelligenz (KI).
Bis vor Kurzem hatten nur wenige von uns von ChatGPT oder Generativer Künstlicher Intelligenz (GenAI) gehört, doch heute ist KI Teil unseres Alltags und erstellt mühelos Texte, Präsentationen, Social-Media-Beiträge und Bilder.
Und die Welt der Forschung in der Chemie bildet da keine Ausnahme. KI ist so einflussreich, dass der Nobelpreis für Chemie 2024 an die Erfinder eines KI-Modells namens AlphaFold verliehen wurde, das die Struktur von Proteinen aus genetischem Code vorhersagen kann. Ein Durchbruch, der die Arzneimittelentwicklung beschleunigen und unser Verständnis von Krankheiten verbessern kann.
In einer Zeit komplexer und sich ständig wandelnder landwirtschaftlicher Herausforderungen hilft KI Chemikern dabei, die nächste Generation nachhaltiger Produkte zu entwickeln, die Pflanzen effizienter und wirksamer vor Schädlingen und Krankheiten schützen.
Im Labor folgt der Prozess zur Entwicklung und Optimierung neuer Pflanzenschutzmittel in der Regel einem iterativen Zyklus – Design, Synthese, Test und Analyse, kurz DSTA.
Ed Emmett, Syngentas Leiter der Unkrautbekämpfungs-Chemie, erklärt: „KI berührt jeden Teil des DSTA-Zyklus, und wir nutzen sie bereits in jeder Phase.“
Um die Auswirkungen von KI in diesem Bereich der Chemie zu verstehen, betrachten wir die einzelnen Schritte des Prozesses genauer.

Künstliche Intelligenz hilft unseren Wissenschaftlern dabei, die nächste Generation nachhaltiger Produkte zu entdecken

Design und Entdeckung
Design ist genau das, wonach es klingt – es ist die Erstellung eines molekularen Bauplans. Doch Chris Baker, Leiter der Computerchemie bei Syngenta in Jealott's Hill, weist auf die enorme Herausforderung hin, eine neue Molekülstruktur zu entdecken: „Der chemische Raum ist riesig – es gibt mehr mögliche Moleküle, als Sterne im Universum. Wo fangen wir überhaupt an?“
Hier zeigt sich einer der größten Vorteile von KI: Sie hilft Forschern, vielversprechende Ansätze zu identifizieren. Baker erklärt: „Computeralgorithmen können diesen Raum viel effizienter erkunden als Menschen.“
Emmett ergänzt: „ChatGPT erstellt Texte als Antwort auf eine Eingabeaufforderung. In der generativen Chemie können wir dasselbe tun, um Molekülstrukturen zu erzeugen.“
Mit den richtigen KI-Modellen und den passenden Eingaben können Wissenschaftler neue molekulare Designs erstellen, deren Eigenschaften digital bewertet und vorhergesagt werden. Das macht die Entwicklung viel schneller und effizienter.
Diese Moleküle müssen strenge Anforderungen in Bezug auf Sicherheit, Wirksamkeit und Nachhaltigkeit erfüllen. Emmett nennt das „Multi-Parameter-Optimierung“ und vergleicht es mit der Suche nach einem neuen Zuhause: „Es gibt so viele Faktoren – man arbeitet nicht linear, weil das zu lange dauern würde.“
Daher setzen Chemiker auf inverses Design: Sie beginnen mit den gewünschten Eigenschaften und leiten daraus die Molekülstruktur ab. Auch hier ist KI ein entscheidender Helfer.
Emmett sieht KI als Mittel zur Verbesserung der „ganzheitlichen Qualität“ des Designs: Moleküle können gezielter, wirksamer, kostengünstiger und nachhaltiger entwickelt werden.
Wie bei anderen generativen KI-Modellen hängt das Ergebnis stark von der Qualität der Eingabe ab. „Man muss genau vorhersagen können, was passieren wird und welche Eigenschaften das Molekül in der Realität haben wird“, sagt Emmett.
Die Herstellung eines Moleküls ist komplex – es muss nicht nur wirksam sein, sondern auch eine lange Liste von Anforderungen erfüllen, von Sicherheit und Kosten bis hin zur Skalierbarkeit für die Massenproduktion.
Es überrascht nicht, dass einige Modelle weiter verfeinert werden müssen. Dennoch sagt Emmett: „Generatives Design ist ein heißes Thema und bereits als Technologie etabliert.“
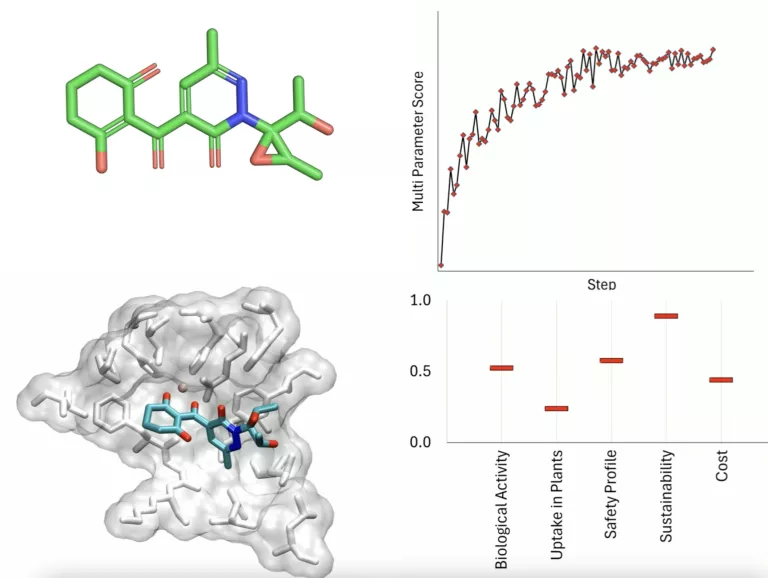
Generatives Design in Aktion: Ein KI-Modell hilft bei der Entwicklung eines Moleküls, das für mehrere Kriterien optimiert ist
Synthese
Die nächste Phase ist die Synthese – der Moment, in dem ein potenzielles Molekül im Labor hergestellt wird. Emmett erklärt: „Wenn Menschen an Chemie denken, stellen sie sich oft vor, wie man Dinge in einem Kolben mischt – KI hilft uns vorherzusagen, was passiert, wenn wir bestimmte chemische Komponenten kombinieren, bevor wir die Reaktion tatsächlich durchführen.“
Doch das ist nicht alles. Bei der Synthese eines neuen Moleküls gibt es viele Unbekannte. Mit einem detaillierten KI-Modell könnten Wissenschaftler Vorhersagen zu Ausbeute, Sicherheit oder sogar nachhaltigen Synthesewegen treffen.
Allerdings bringt die Synthese auch neue Herausforderungen mit sich.
Elizabeth Jones, Leiterin „Data for Design“ bei Syngenta, sagt: „Die Synthese ist komplex, weil Modelle Strukturen vorschlagen können, die synthetisch nicht machbar oder viel zu teuer wären.“
Guillaume Berthon, Leiter der digitalen chemischen Synthese bei Syngenta, ergänzt: „Derzeit werden etwa 30–40 % der Moleküle, die wir herstellen wollen, aufgrund von Syntheseproblemen verworfen.“
Um dieses Problem zu lösen, arbeitet Syngenta mit IBM und MIT zusammen und nutzt Natural Language Processing (eine Methode, mit der Computer menschliche Sprache verstehen), um sogenannte „Retrosynthese-Vorhersagen“ zu treffen.
Das bedeutet, Vorhersagen über alle möglichen Wege zu machen, wie ein Molekül im Labor zusammengesetzt werden könnte – basierend auf weltweiten Daten. Die Modelle dienen als Leitfaden für die Planung der Molekülherstellung.
Die Herausforderung: Modelle sind nur so gut wie die Daten, auf denen sie basieren. Öffentliche Daten enthalten oft nur erfolgreiche Reaktionen, nicht die fehlgeschlagenen. Berthon sagt: „Die chemischen Räume, die uns interessieren, sind oft schlecht dokumentiert, sodass öffentliche Daten wenig helfen.“
Dabei können gescheiterte Reaktionen wertvolle Erkenntnisse liefern. „Wir müssen immer auf Verzerrungen achten. Schlechte Datenqualität kann die Modelle verfälschen“, sagt Emmett.
Um Modelle gut zu trainieren, müssen Daten auffindbar, zugänglich, interoperabel und wiederverwendbar sein – kurz FAIR. „FAIR-Daten sind entscheidend für die Modellbildung“, sagt Emmett, „aber die digitale Infrastruktur dafür muss noch weiterentwickelt werden.“
Wichtig ist, in die richtige Datenaufbereitung für maschinelles Lernen zu investieren.
Das schafft einen virtuellen Kreislauf: Hochwertige Daten führen zu besseren Modellen, die wiederum bessere Syntheseverfahren inspirieren.
Emmett fasst zusammen: „Wir müssen unsere eigenen Daten mit öffentlichen Daten kombinieren, um die bestmöglichen Vorhersagemodelle zu erstellen. Diese KI-Modelle ermöglichen es, wertvolle Erkenntnisse zu gewinnen.“

Elizabeth Jones, Leiterin des Teams "Data for Design" und Chris Baker, Leiter Computergestützte Chemie bei Syngenta Jealott's Hill
Testphase
Als Nächstes folgt die Testphase. Neue Pflanzenschutzmoleküle durchlaufen strenge und umfassende Prüfungen – und auch hier spielt KI eine entscheidende Rolle.
Nehmen wir die Pflanzenbiologie: Wenn ein neues Molekül entwickelt wird, um zu prüfen, ob es eine Pflanzenkrankheit wirksam bekämpft, muss es getestet werden. Traditionell bedeutete das, dass Forscher im Gewächshaus oder auf Versuchsfeldern durch Reihen von Pflanzen gingen und visuelle Beobachtungen machten, um den Erfolg zu beurteilen.
Doch Emmett sagt: „Mit bloßem Auge zu prüfen, ob etwas wirkt, ist subjektiv. KI-Bildgebungstechnologie kann uns deutlich reichhaltigere Daten liefern. Es überrascht nicht, dass alle in der Forschung diese Möglichkeit erkunden.“
Hochwertigere Daten sind jedoch nur einer der Vorteile, die KI in diesem Bereich bietet.
Berthon erklärt: „Der entscheidende Schritt ist, aus diesen Daten Schlussfolgerungen zu ziehen. Es geht um die zentrale Frage: ‚Angesichts meines Wissens über den Datenerzeugungsprozess und die aktuellen Daten – wie wahrscheinlich ist es, dass meine Verbindung die gewünschte Eigenschaft hat?‘
„Derzeit machen wir das manuell, aber KI wird uns hier mit probabilistischen (sogenannten Bayes’schen) Modellen unterstützen, die die Berechnungen für uns übernehmen und unsere Verzerrungen beseitigen“, sagt er.
Jones ergänzt: „Anstatt uns auf subjektive und qualitative menschliche Urteile zu verlassen, arbeiten wir intensiv mit Bildverarbeitungsmodellen, die die Ergebnisse von Tests und Analysen automatisch bewerten.“
Diese Automatisierung ist unverzichtbar, wenn potenzielle Moleküle in großem Maßstab getestet werden sollen. Automatisierte Bilderkennung bringt Präzision in die Prüfung von Blättern oder Pflanzen im Gewächshaus. Baker fügt hinzu: „Wir setzen diese Technologie zunehmend auch im Feld ein, indem wir Drohnen nutzen, um wertvolle Daten darüber zu sammeln, wie Verbindungen und Moleküle in der Praxis wirken.“
Ein weiterer Weg, wie KI die Testphase verändert hat, ist das sogenannte „Active Learning“. Früher arbeiteten Chemiker an einer Verbindung, und die vielversprechendste wurde getestet. Mit KI lässt sich dieser Prozess verbessern.
Baker sagt: „Der KI-Algorithmus kann uns sagen, welches die wichtigste Verbindung ist, die getestet werden sollte. Dieser proaktive Ansatz ermöglicht es uns, mehr hochwertige Testdaten zu generieren, die wir wiederum nutzen können, um unsere KI-Modelle weiter zu verbessern.“

Bilderkennungsmodelle können die Ergebnisse von Assays und Tests automatisch bewerten
Analyse
Tests erzeugen eine große Menge an Daten – hier kommt die Analyse ins Spiel. „Eine gute Analyse der durch Tests gewonnenen Daten ermöglicht die Erstellung der besten Eingaben für den nächsten GenAI-Designschritt“, sagt Emmett.
Analyse und Design gehen daher Hand in Hand, denn wie Emmett erklärt: „Wir arbeiten iterativ – gute Analyse führt zu gutem Design und ermöglicht es uns, unser Ziel so effizient wie möglich zu erreichen.“
KI-Algorithmen können große Datensätze verarbeiten und analysieren, um Muster, Trends und Zusammenhänge zu erkennen, die für traditionelle statistische Methoden und für Menschen zu komplex wären.
Aus diesen Mustern kann KI dann präzise Vorhersagen über die Eigenschaften von Molekülen treffen, die noch hergestellt werden müssen – etwa ihre Wirksamkeit oder Sicherheit. All dies trägt dazu bei, die Kosten für Experimente zu senken und den Entdeckungsprozess zu beschleunigen.
„Je besser die Analyse, desto weniger Design-, Synthese-, Test- und Analysezyklen sind nötig“, sagt Emmett.
KI hat das Potenzial, den gesamten DSTA-Zyklus grundlegend zu verändern und eine Fülle an datengestützten Erkenntnissen freizusetzen, die hochwertige Innovationen schneller und nachhaltiger vorantreiben.
Mit dem technologischen Fortschritt erschließt die wissenschaftliche Forschung mehr Daten als je zuvor. „KI hilft uns, die schiere Menge an Informationen zu verstehen – und macht sie zu einem unverzichtbaren Werkzeug für Wissenschaftler, um Landwirten weltweit beim Schutz ihrer Kulturen zu helfen“, sagt Emmett.
